Faceclick: A lightweight Emoji picker with keyword search

Here it is:
-
Faceclick Git repo - Read it, Git it!
-
Faceclick Live test page - Try it!
Faceclick has two goals:
-
Let the user pick Emoji by group or keyword search and display labels on rollover.
-
Be as small in file size as possible.
Small size is a goal
Faceclick has a total payload (including CSS) of 70Kb (not minified, not gzipped). This is accomplished by applying a very simple type of substitution "compression" in the Emoji labels and keywords, which is explained below.
On the right is very tall vector image of the source code of Faceclick.
The CSS file is shown for scale, with a height of 83 lines.
The JavaScript file has been color-coded and labeled with the following sections:
-
A: 208 lines - The main program source.
-
B: 6 lines - The start of the data section and the Emoji category groups.
-
C: 32 lines - The 'word' list (explained below).
-
D: 874 lines - The main Emoji data including labels and keywords.
The source code image made with: SVG Sourcecode Shapes (a Ruby script).
Screenshot, features

The search box searches across keywords and labels. The screenshot shows results for "plant".
Other examples of keyword searching:
-
"green" gives you 9 matching Emoji including a green heart, trees, and salad.
-
"sad" gives 21 appropriate options including crying faces and broken hearts.
You can also go to one of four groups of Emoji by clicking on one of the tabs along the top. The groups should be pretty familiar since they come from the Unicode standard, but there are less of them because I chose to combine some of the existing categories together. (This is all completely customizable in the data tools. See below.)
Labels show up when you roll over an emoji, which I find very useful to figure
out what some of them are supposed to be! (The tooltip is provided by the HTML
title attribute.)
Usage
See the repo README for full installation and usage instructions.
Basic installation and usage look like this:
<script src="faceclick.js"></script>
<script>
FC.attach("my_button", "my_text_box");
</script>
Where my_button and my_text_box are the IDs of existing DOM elements.
Faceclick exposes all of its methods, so you can compose your own usage for as much control as you need.
You are also encouraged to take the provided CSS and modify, incorporate, or replace it to match your site as needed.
The Emoji data
The UI for Faceclick isn’t too interesting other than the goals of being unusually small, readable, and flexible.
The real core feature of Faceclick is the compactness of the data. This is where I spent most of my development efforts.
The primary source of the Emoji data is this excellent project: https://emojibase.dev/
The raw files from the Emojibase project can be found here (16.0.3 is the current version as I’m writing this): https://cdn.jsdelivr.net/npm/emojibase-data@16.0.3/en/
The upstream origin of this data, by the way, is the Unicode standard: https://unicode.org/Public/emoji/
Whittling down the data
My first challenge was to pick which Emoji I wanted to include in my picker. The full set with all possible combinations of skin colors, genders, and hairstyles, is pretty huge. I want a big set of Emoji, but I don’t need everything. Furthermore, I’m relying on native rendering, and the more complicated combinations aren’t available on a lot of platforms anyway.
I initially started off using jq, the command line tool for manipulating
JSON. But I quickly realized that I could just use Ruby and have a language I
actually know.
For a while, I had half a dozen Ruby scripts to massage and chop up the full
Emojibase set.
But maintaining a pipeline of scripts eventually got tiring and I combined them
all into a single program, customizer.rb.
Customizer results:
-
735,588 bytes - data.json - Emojibase original
-
136,623 bytes - myemoj.json - customizer output
As you can see, the customized dataset is 5 times smaller than the original. That’s a good start!
Another Ruby script makes an HTML "contact sheet" to view the resulting set in a browser. The sheet also includes stats about the number of items and bytes of data each part will require.
Here’s the contact sheet for my Emoji set:
By the way, I absolutely expect people to disagree with some of the choices
I’ve made, so the customizer is fully commented. Comment out or change that
script to make your own dataset. All of these tools, and the data sources are
in the data/ directory of the repo, which has its own README.
Storing the data efficiently
My second challenge was to store the Emoji, labels, groups, and keywords as compactly as I could while also keeping the format simple, readable, and understandable.
I created at least three different layouts for the Emoji data. One of the key challenges is that with over a thousand items, any additional syntax adds up pretty quickly.
For example, let’s say we want to store the first four letters of the alphabet. An obvious solution is an array:
["A","B","C","D"]
The additional syntax for string quoting and comma separation means that we’ve turned 4 characters (A B C D) into 17!
I kept removing syntax elements (like objects with property labels) from my data structures until I finally settled on the simple solution of storing my lists as space-separated strings:
"A B C D"
9 characters, including the quote marks, is much better than 17. Splitting a string by a fixed marker is utterly trivial for modern browsers.
A space-separated string is very cheap and readable encoding indeed!
Compression by word de-duplication
My first observation when I started this project was that there was quite a bit of duplication of whole words between the keywords and labels and across Emoji. (One thing that exacerbates the keyword/label duplication is that the Unicode standard mentions that many of the keywords are synthesized by breaking the labels into words.)
There was clearly some opportunity to "compress" this data by de-duplicating the individual words in labels and keyword lists.
Data compression is a fascinating topic and I’m a total noob, but I have done enough simple things like run-length encoding over the years to know that if you aren’t thoughtful about it, you’re more likely to make your data larger. (Try making a zip file out of an existing zip or highly random data and you’re probably going to end up with a larger file because of the overhead of the container, etc.)
Once I’d settled on a word de-duplication scheme, it became clear that there were two parameters I could use to determine if a word should be de-duped and turned into a reference:
-
The minimum length of the word.
-
The number of times the word appears.
It gets really hard to figure out the right numbers for these parameters because it depends on the statistical distribution of the words in the actual dataset. Plus there are other factors, e.g. having a smaller amount of items makes the index numbers smaller on average (fewer digits). So things don’t just scale up and down linearly! You can see this visually in the graph below.
So I parameterized my script and wrote another Ruby script to test out the combinations.
I kept the results of my experiment (the script is also in the data/
directory so you can try out your own experiments). And I just spent an hour
figuring out how to make Gnuplot display this, so we may as well look at it:
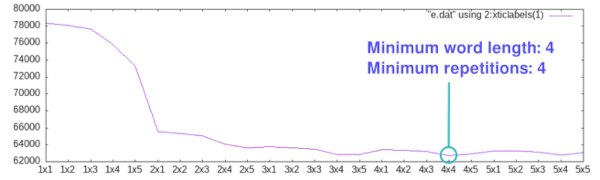
In the chart above, "1x2" means a word of a single character repeated twice. As you can see, the compression result starts to get much better when we get to words of at least 2 characters.
This makes complete sense because it takes at least 2 characters for the index indicator and the numeric index itself. (And there’s no way to make this smaller without getting into complete overkill like binary encoding. Source readability, even of the data, is still a goal of this project, as I describe in more detail below.)
As you can see, the sweet spot for my particular dataset, was a word length of 4 characters or higher, repeated at least 4 times in the dataset (4x4).
As with any good experiment, the results were a little surprising to me - I was expecting a smaller repetition count to perform better. I’m so glad I took a moment to do this because it was a super easy way to wring a last 5-8Kb savings versus my best guess at the parameters!
Final format and results
So, armed with the idea of using space-separated strings rather than arrays or objects and the right size of word dictionary, I settled on a format.
Here’s a couple examples taken straight out of the actual data file:
['😀','$93 $0','cheerful cheery $56 $256 $345 $14 $18 $128'], ['😃','$93 $0 $2 big $32','$193 $56 $55 $43 $14 $18 $128 yay'],
The format is:
[<emoji>, <label>, <keywords>]
As you can see, there are a lot of dictionary word references, which take the
form of $xx. $93 is the index number of "grinning" and $0="face". So the
first label is "grinning face".
Note that "face" is $0 because I sorted the word list by frequency of usage,
so the most-used indexes start at single digits. It should come as no surprise
that the most commonly used word in Faceclick is face. 😀
You can also see four verbatim words that didn’t meet the 4x4 criteria: "cheerful", "cheery", "big", and "yay".
So how well did this compress the data from the original?
-
735,588 bytes - data.json - Emojibase original
-
136,623 bytes - myemoj.json - customizer output
-
63,045 bytes - mydata.js - final data used in library
As you can see, storing lists as strings and using tuned word substitution cut my dataset by more than half. And it’s less than 10% of the original set from Emojibase (though I’ve thrown away a lot of information, so it’s not a totally fair comparison).
Finally, believe it or not, source readability is also one of my goals. I hate
it when I open up a JS file in my text editor and find that it includes giant
lines of minified source. So rather than just using Ruby’s JSON.generate(),
I’m hand-rolling the JavaScript output and wrapping lines at a reasonable
length. (Thus the ability to display it a super tall vector image on this
page!)
Data at runtime
To "decompress" at runtime, all I need to do is split the strings by space, replace any indexed words, and then re-join the strings. Here’s the entire thing:
// From: ['X','$1 $2','foo $3']
// To: {glyph:'X', label: 'big dog', tags: 'foo bar big dog'}
FC.data.emoji.forEach(function(e, i){
var glyph = e[0];
var label = e[1];
var tags = e[2];
label = idx2txt(label.split(' ')).join(' ');
tags = idx2txt(tags.split(' ')).join(' ');
// Write expanded object in place of original
FC.data.emoji[i] = {
glyph: glyph,
label: label,
tags: tags + ' ' + label,
};
});
Note: The term "tags" is used in the Unicode dataset. These are the "keywords".
And here’s the indexed word replacement function used above (idx2txt is shorthand for "index to text"):
// Replaces '$42' with word at index 42
function idx2txt(wlist){
wlist.forEach(function(w,i){
if(w[0] === '$'){
var idx = w.substring(1);
wlist[i] = words[idx];
}
});
return wlist;
}
As you may have noticed above, I also join the label string to the tags. Words in the label have already been removed from the tags list, so there’s no duplication.
It’s funny how my final format is not only smaller than a more complicated data structure, it’s also much easier to make, easier to read, and easier to use. It eventually felt "obvious" to me in a way that really solid, simple solutions so often do.
This part of exploratory programming where better, simpler solutions eventually surface over time always reminds me of the quote from a letter by mathematician Blaise Pascal, which translates into English as:
"I have made this longer than usual because I have not had time to make it shorter."
Now that the keyword list is just a single string, it makes filtering out Emoji that don’t match the input search text as simple as this line:
if(emoji.tags.indexOf(search_text) === -1){ return; }
Why?
Why the obsession with getting the size down, you ask? Well, first of all, I think it’s a perfectly worthy goal all on its own. Anything delivered over a network on a regular basis should have at least a little effort put into it to keep it from being wasteful!
But my specific reason was that I made this Emoji picker for my Famsite mini social media website and, at the time, that weighed just 40Kb (frontend and backend, total).
I didn’t "golf" down Famsite to make it as small as possible. It’s just that 40Kb is a lot of functionality when you make things stupidly simple and don’t include any 3rd party libraries.
So perhaps you can understand why adding a 300Kb+ library (and those are the good ones!) to my 40Kb project felt like adding a house to my bicycle because I wanted to add a bell.
As it is, Faceclick has more than doubled the size to 110Kb. Oh no! Ha, but it was totally worth it.
What about fuzzy?
One of my explicit goals when I started this project was that the keyword search would use "fuzzy" matching.
I went as far as making a stand-alone example page for the fuzzy matching method I’m using:
I love fuzzy searching for producing matches to long, complicated sets of strings, e.g. file paths in source code repositories.
But it turns out that the kind of fuzzy searching I was using is worse than useless for short keyword matching. My search results improved immediately when I ripped it out and replaced it with the single line "dumb" string matching shown above in the runtime section. Oh well!